Microsoft DP-700 - Implementing Data Engineering Solutions Using Microsoft Fabric Certification Exam
Question #6 (Topic: demo questions)
HOTSPOT You need to meet the development requirements for the FeedbackJson column
How should you complete the Transact SQL query? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
A.
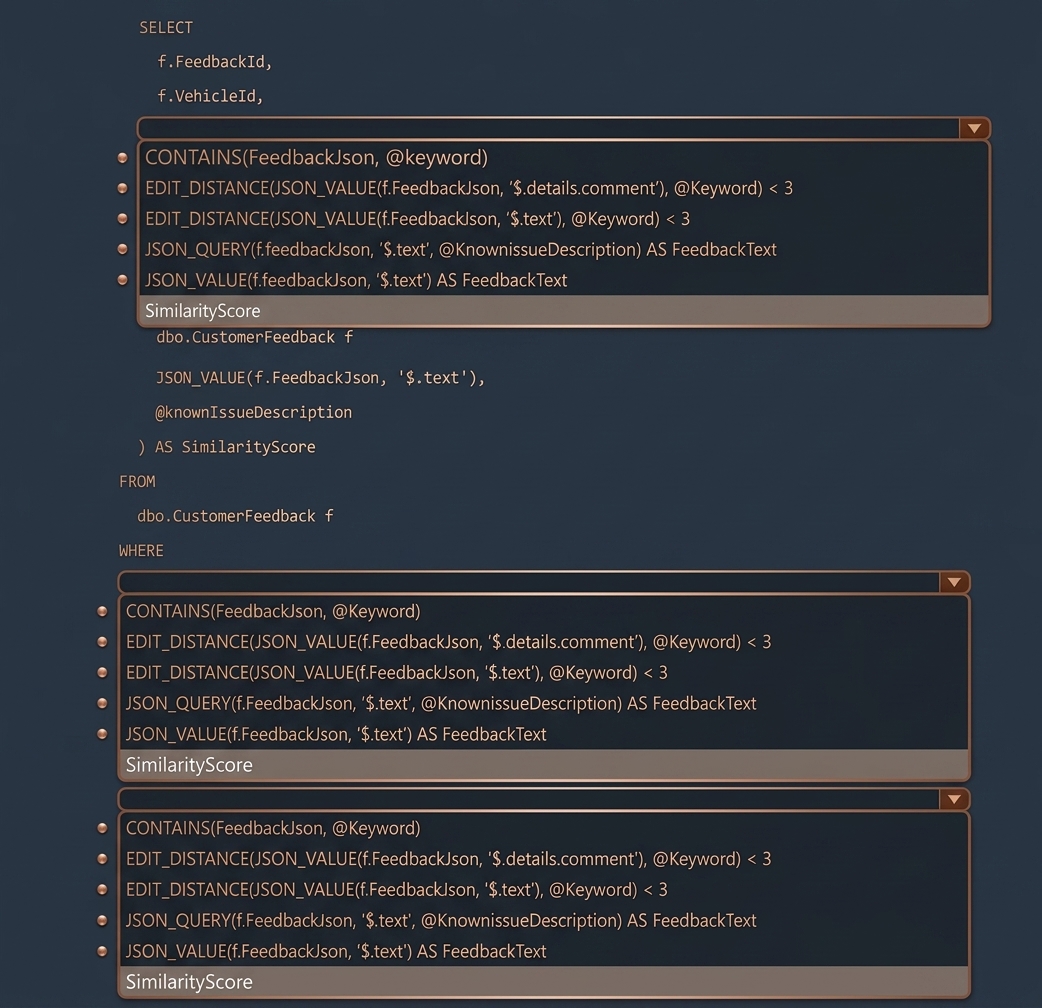
Correct Answer: A
Explanation:
These three selections are the correct way to complete the query because they align exactly with the stated requirements for the FeedbackJson column. First, to extract the customer feedback text from the JSON document, the correct expression is JSON_VALUE(f.FeedbackJson, '$.text') AS FeedbackText. Microsoft documents that JSON_VALUE is used to extract a scalar value from JSON, while JSON_QUERY is used for returning an object or array. Since $.text is the textual feedback string, JSON_VALUE is the correct function. Second, to filter rows where the JSON text contains a keyword, the best choice is CONTAINS(FeedbackJson, @Keyword). The scenario explicitly states that FeedbackJson already has a full-text index, and Microsoft documents that CONTAINS is the full-text predicate used in the WHERE clause to search full-text indexed character data. That makes it more appropriate than using EDIT_DISTANCE for keyword filtering. Third, to order the results by similarity score, highest first, the correct item is SimilarityScore in the ORDER BY clause, which would be paired with DESC in the query. This matches the requirement to sort by the computed fuzzy similarity value. The DP-800 study guide specifically includes writing queries that use fuzzy string matching functions such as EDIT_DISTANCE, which supports the earlier computed SimilarityScore expression in the query. JSON_VALUE(f.FeedbackJson, '$.text') AS FeedbackText CONTAINS(FeedbackJson, @Keyword) SimilarityScore
Question #7 (Topic: demo questions)
You need to recommend a solution that will resolve the ingestion pipeline failure issues. Which two actions should you recommend? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
Correct Answer: D, E
Explanation:
The two correct actions are D and E because the ingestion failures are caused by malformed JSON and duplicate payloads, and these two controls address those two problems directly. Microsoft’s JSON documentation states that SQL Server and Azure SQL support validating JSON with ISJSON, and Microsoft specifically recommends using a CHECK constraint to ensure JSON text stored in a column is properly formatted. For the duplicate-payload issue, creating a unique index on a hash of the payload is the appropriate design. Microsoft documents using hashing functions such as HASHBYTES to hash column values, and SQL Server allows a deterministic computed column to be used as a key column in a UNIQUE constraint or unique index. That makes a persisted hash-based computed column plus a unique index a practical and exam-consistent way to reject duplicate payloads efficiently. The other options do not solve the stated root causes: Snapshot isolation addresses concurrency behavior, not malformed JSON or duplicate payload detection. A trigger to rewrite malformed JSON is not the right integrity control and is brittle. Foreign key constraints enforce referential integrity, not JSON validity or duplicate-payload prevention
Question #8 (Topic: demo questions)
You need to recommend a solution for the development team to retrieve the live metadata. The solution must meet the development requirements. What should you include in the recommendation?
Correct Answer: C
Explanation:
The best recommendation is to use an MCP server. In the official DP-800 study guide, Microsoft explicitly lists skills such as configuring Model Context Protocol (MCP) tool options in a GitHub Copilot session and connecting to MCP server endpoints, including Microsoft SQL Server and Fabric Lakehouse. That makes MCP the exam-aligned mechanism for enabling AI-assisted tools to work with live database context rather than static snapshots. This also matches the stated development requirement: the team will use Visual Studio Code and GitHub Copilot and needs to retrieve live metadata from the databases. Microsoft’s documentation for GitHub Copilot with the MSSQL extension explains that Copilot works with an active database connection, provides schema-aware suggestions, supports chatting with a connected database, and adapts responses based on the current database context. Microsoft also documents MCP as the standard way for AI tools to connect to external systems and data sources through discoverable tools and endpoints. The other options do not satisfy the “live metadata” requirement as well: A .dacpac is a point-in-time schema artifact, not live metadata. A Copilot instruction file provides guidance, not live database discovery. Including the database project in the repository helps source control and deployment, but it still does not provide live database metadata by itself.
Question #9 (Topic: demo questions)
You need to generate embeddings to resolve the issues identified by the analysts. Which column should you use?
Correct Answer: B
Explanation:
The correct column to use for generating embeddings is incidentDescrlption because embeddings are intended to represent the semantic meaning of rich textual content, not simple categorical, numeric, or location-only values. Microsoft’s DP-800 study guide explicitly includes skills such as identifying which columns to include in embeddings, generating embeddings, and implementing semantic vector search for scenarios where users need to find similar records based on meaning rather than exact matches. In this scenario, analysts report that it is difficult to find similar incidents based on details such as weather, traffic conditions, and location. Those are descriptive context elements that are typically captured in a free-text incident description field. An embedding generated from incidentDescrlption can encode the semantic relationships among these narrative details, making it suitable for similarity search, semantic search, and RAG retrieval. Microsoft documentation on vectors and embeddings explains that embeddings are generated from text data and then stored for vector search to find semantically related items. The other options are weaker choices: vehicleLocation is too narrow and usually better handled with geospatial filtering, not embeddings. incidentType is likely categorical and too low in semantic richness. SeverityScore is numeric and not appropriate as the primary source for semantic embeddings. Microsoft also notes that when multiple useful attributes exist, you can either embed each text column separately or concatenate relevant text fields into one textual representation before generating the embedding. But among the options given, the best and most exam-aligned answer is the textual narrative column: incidentDescrlption.
Question #10 (Topic: demo questions)
You need to configure models for the project.
What are two possible ways to achieve the goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
Correct Answer: A, D
Explanation:
When working with Microsoft Dynamics 365 Finance and Operations, you should never modify an existing model directly. Instead, customization is done through extensions.
When working with Microsoft Dynamics 365 Finance and Operations, you should never modify an existing model directly. Instead, customization is done through extensions.
✅ A. Overlay the existing FinanceExt model and populate the solution definition.
This is a valid way to configure the project model by using the existing model and defining it in the solution. Historically, overlaying was used to modify existing application objects.
❌ B. Modify the DefaultModelForNewProject setting in the DefaultConfig.xml file and name the model FinanceExt.
This only changes the default model name for new projects. It does not configure or extend the model required for the project.
❌ C. Create a new model that extends the existing FinanceExt model.
Models do not extend other models directly. Instead, a model can reference another model. Therefore, this statement is not correct.
✅ D. Extend the existing FinanceExt model and populate the project model definition.
This is the recommended approach. You create extensions and configure the project so that it uses the existing FinanceExt model.