Microsoft DP-700 - Implementing Data Engineering Solutions Using Microsoft Fabric Certification Exam
Question #1 (Topic: demo questions)
You need to populate the MAR1 data in the bronze layer.
Which two types of activities should you include in the pipeline? Each correct answer presents part
of the solution
Correct Answer: A, B
Explanation:
MAR1 has seven entities, each accessible via a different API endpoint. A ForEach activity is required
MAR1 has seven entities, each accessible via a different API endpoint. A ForEach activity is required
to iterate over these endpoints to fetch data from each one. It enables dynamic execution of API calls
for each entity.
The Copy data activity is the primary mechanism to extract data from REST APIs and load it into the
bronze layer in Delta
Question #2 (Topic: demo questions)
You need to ensure that usage of the data in the Amazon S3 bucket meets the technical
requirements.
What should you do?
Correct Answer: B
Explanation:
To ensure that the usage of the data in the Amazon S3 bucket meets the technical requirements, we
To ensure that the usage of the data in the Amazon S3 bucket meets the technical requirements, we
must address two key points:
Minimize egress costs associated with cross-cloud data access: Using a shortcut ensures that Fabric
does not replicate the data from the S3 bucket into the lakehouse but rather provides direct access to
the data in its original location. This minimizes cross-cloud data transfer and avoids additional egress
costs.
Prevent saving a copy of the raw data in the lakehouses: Disabling caching ensures that the raw data
is not copied or persisted in the Fabric workspace. The data is accessed on-demand directly from the
Amazon S3 bucket.
Question #3 (Topic: demo questions)
HOTSPOT
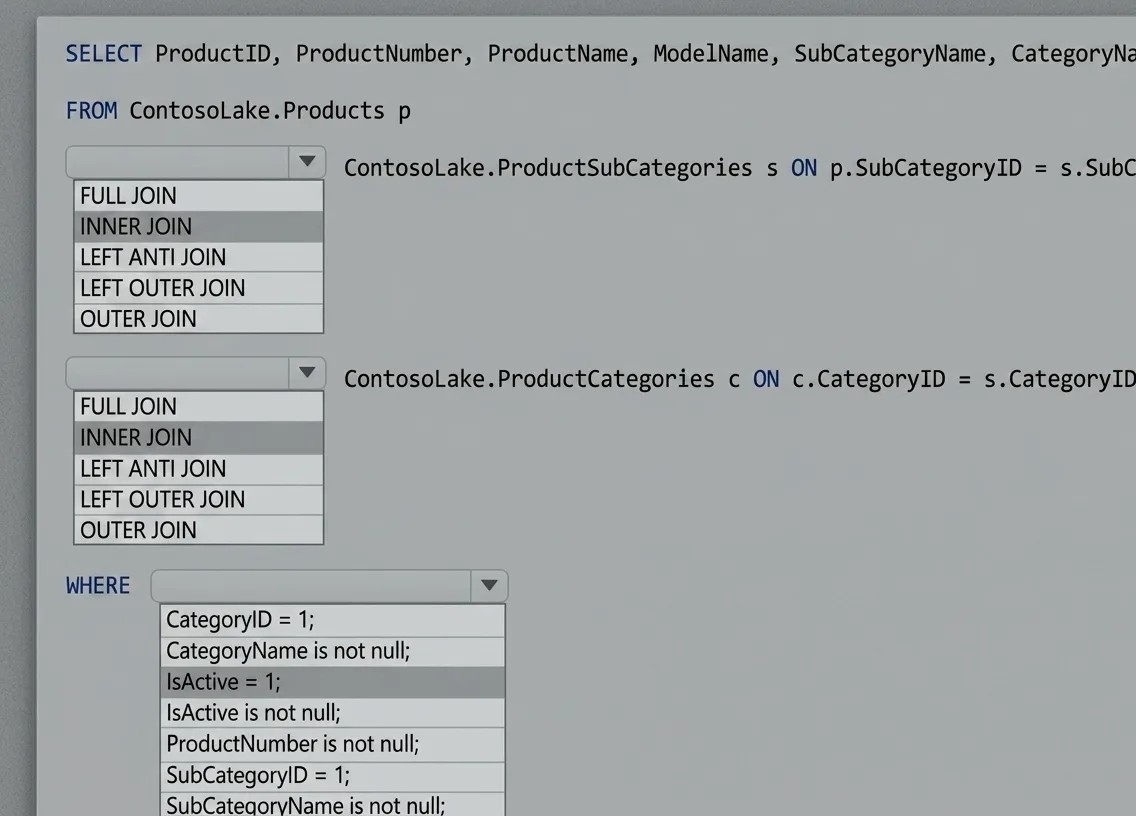
You need to create the product dimension.
How should you complete the Apache Spark SQL code? To answer, select the appropriate options in
the answer area.
NOTE: Each correct selection is worth one point.
A.
Correct Answer: A
Explanation:
A screenshot of a computer Description automatically generated
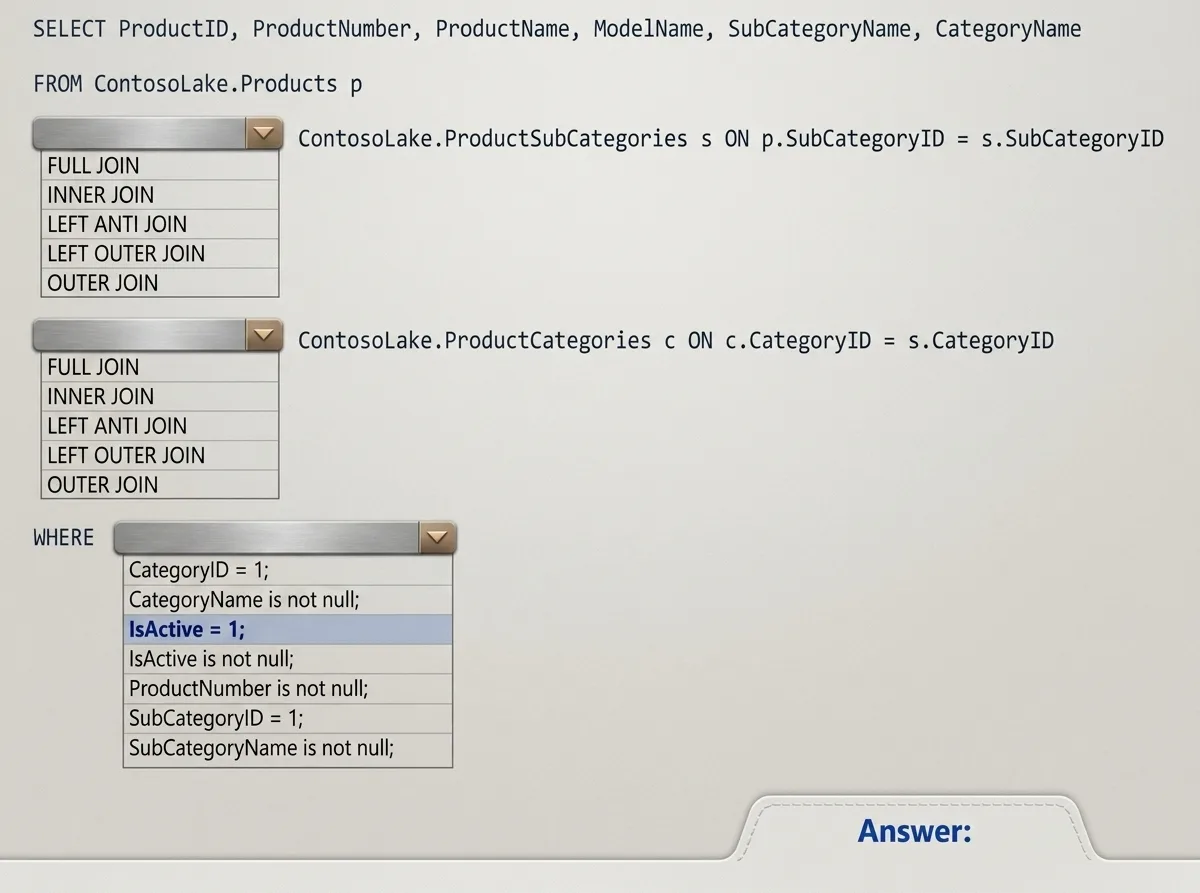
A screenshot of a computer Description automatically generated
Join between Products and ProductSubCategories:
Use an INNER JOIN.
The goal is to include only products that are assigned to a subcategory. An INNER JOIN ensures that
only matching records (i.e., products with a valid subcategory) are included.
Join between ProductSubCategories and ProductCategories:
Use an INNER JOIN.
Similar to the above logic, we want to include only subcategories assigned to a valid product
category. An INNER JOIN ensures this condition is met.
WHERE Clause
Condition: IsActive = 1
Only active products (where IsActive equals 1) should be included in the gold layer. This filters out
inactive products.
Question #4 (Topic: demo questions)
You need to ensure that the data analysts can access the gold layer lakehouse.
What should you do?
Correct Answer: C
Explanation:
Data Analysts' Access Requirements must only have read access to the Delta tables in the gold layer
Data Analysts' Access Requirements must only have read access to the Delta tables in the gold layer
and not have access to the bronze and silver layers.
The gold layer data is typically queried via SQL Endpoints. Granting the Read all SQL Endpoint data
permission allows data analysts to query the data using familiar SQL-based tools while restricting
access to the underlying files.
Question #5 (Topic: demo questions)
HOTSPOT
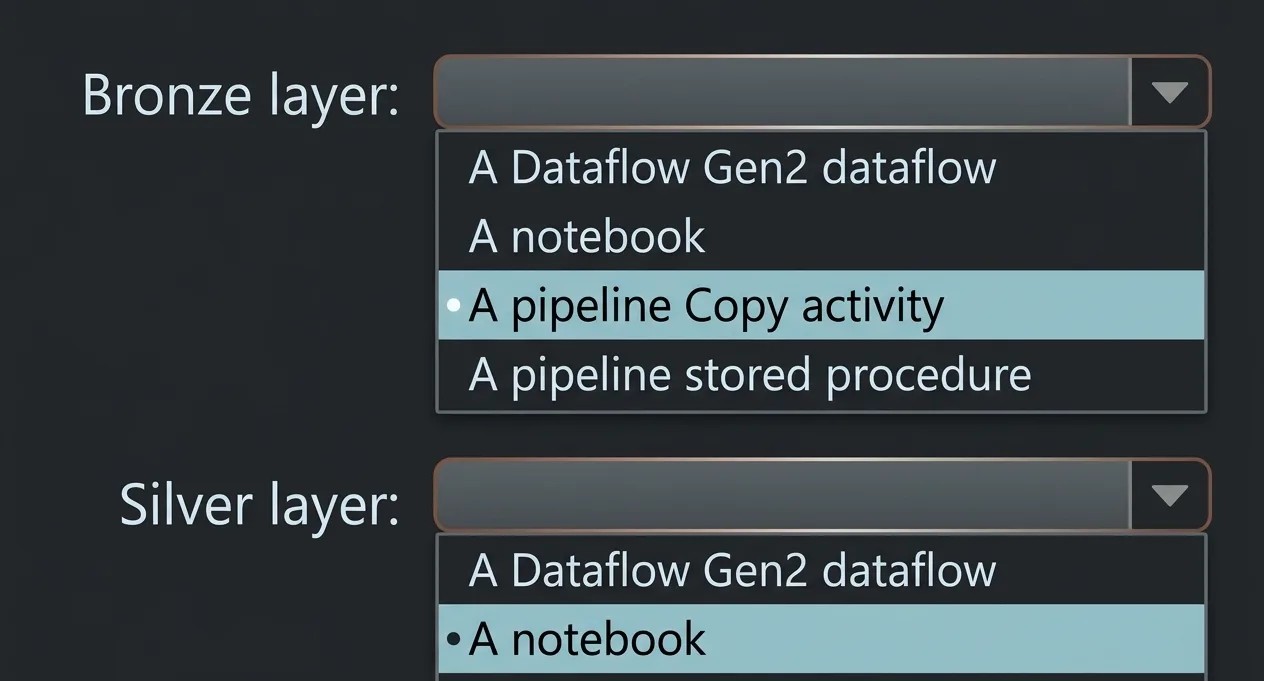
You need to recommend a method to populate the POS1 data to the lakehouse medallion layers.
What should you recommend for each layer? To answer, select the appropriate options in the answer
area.
NOTE: Each correct selection is worth one point.
A.
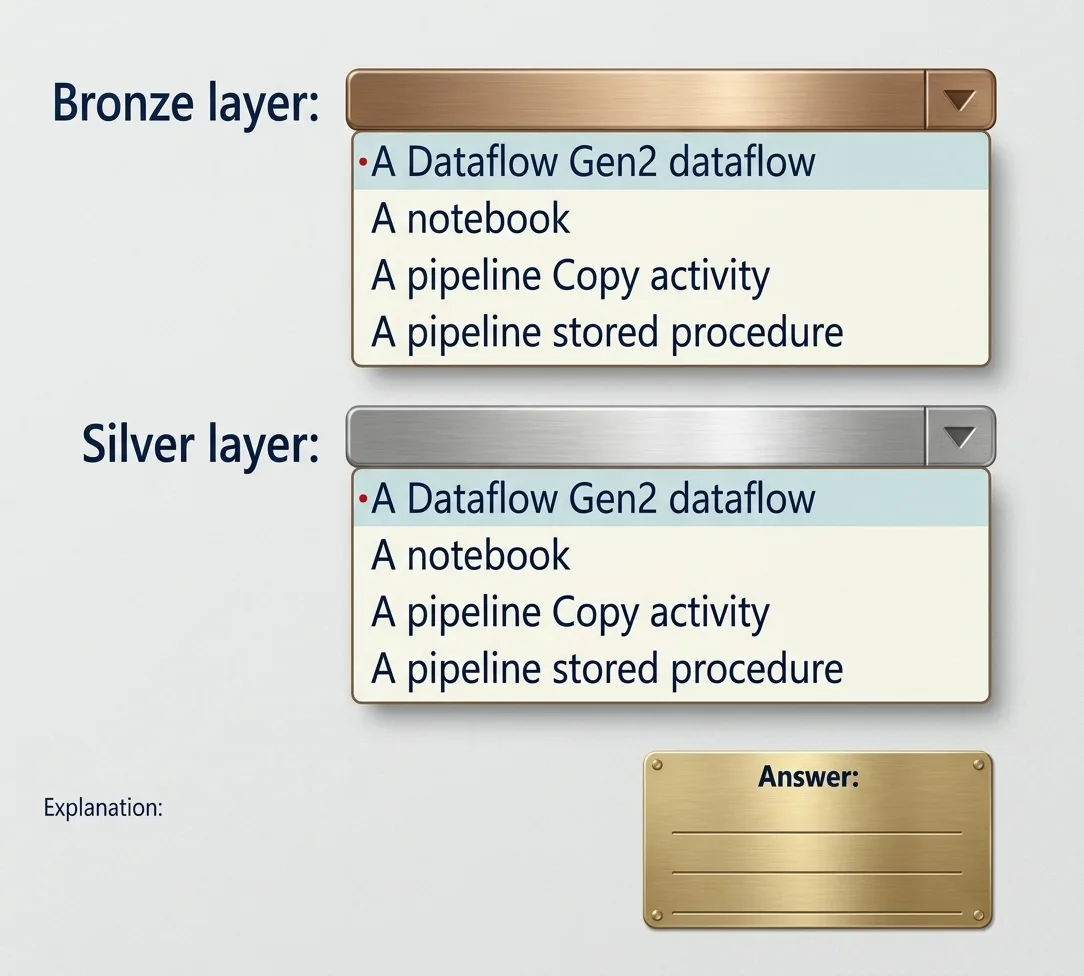
Correct Answer: A
Explanation:
A screenshot of a computer Description automatically generated